2006-08-17
_ 日本語と n-gram でも Zipf の法則は成り立つか
Zipf の法則というのは以下のようなものです。英語で書かれた長編小説を用意します(小説でなくてもいいんだけど)。そして、本文中に出てくる英単語を頻度順に並べます。すると、第2位の単語の頻度は第1位の単語の頻度の半分になります。第10位の単語の頻度は第1位の単語の頻度の1/10です。第100位の単語の頻度は第1位の単語の頻度の1/100です。そんな感じの法則です。リンク先にもあるように対数グラフにプロットするときれいな直線になります。
さて、Zipf の法則は日本語に対して当てはまるでしょうか。とはいっても、日本語は英語みたいに単語毎に区切ることが簡単ではないので、ここでは n-gram を使います。2文字毎に文を区切って、その2文字を単語だと思って頻度を数えます。ひらがなと漢字だけを対象にしました。日本語のデータとしてはこの日記の本文を使いました。
REG = /([ぁ-ん亜-腕]([ぁ-ん亜-腕]))/e
H = Hash.new(0)
def count(line)
while REG =~ line
word = $1
c = $2
H[word] += 1
line = c + (Regexp.last_match.post_match || '')
end
return line
end
def read_and_count(io)
ret = ''
io.each_line{|l|
ret += l.chop
ret = count(ret)
}
end
def plot2(h)
h = h.to_a.sort{|a, b| b[1] <=> a[1] }
500.times{|n|
e = h[n]
puts "#{n+1} #{e[1]}"
}
end
read_and_count(ARGF)
plot2(H)
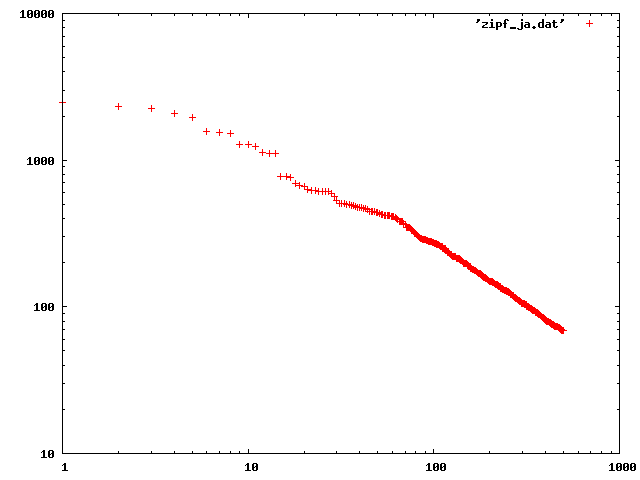
結果です。横軸が順位、縦軸が頻度です。割ときれいな直線になっていると言えなくもないですね。英語の場合、直線の傾きはだいたい -1 になるそうです。しかし、この場合、直線の傾きは約 -0.734 です。この違いはどこから来るのでしょうか。英語と日本語の違い?
■追記(2006/8/21)。
本日のリンク元
- 35 http://www.jmuk.org/d/
- 5 http://nihongo.homeip.net/word/Zipf/
- 4 http://feedbringer.net/feed
- 4 http://1470.net/mm/
- 3 http://threecarhire.co.uk/Blog/BlogViewPagev.aspx
- 3 http://jmuk.org/d/
- 2 http://www.jmuk.org/diary/2006/08
- 2 http://www.flog.jp/comment.php/14354
- 2 http://i-know.jp/kanou/
- 2 http://d.hatena.ne.jp/otsune/
- 2 http://b.hatena.ne.jp/myui/
- 2 http://b.hatena.ne.jp/faerie/
- 2 はてなアンテナ[yshl]
- 2 http://a.hatena.ne.jp/relate?uid=WikiFan
- 2 はてなアンテナ[nobsun]
- 2 はてなアンテナ[no_ri]
- 2 はてなアンテナ[nmkk]
- 2 はてなアンテナ[mintleaf]
- 2 はてなアンテナ[kourindrug]
- 2 はてなアンテナ[essa]
- 2 はてなアンテナ[arn]
- 1 http://www.dm4lab.to/~kjana/ant.html
- 1 http://www.chohkan.org/fr/feedshow.php?f=http://fe...
- 1 http://www.asahi-net.or.jp/~dp8h-izn/link.html
- 1 http://ukgk.g.hatena.ne.jp/faerie/
- 1 http://pc.matome.jp/keyword/N-gram
- 1 http://mmmemo.1470.net/mm/mylist.html/642
- 1 http://i-know.jp/nabesin/
- 1 http://i-know.jp/monolith/listall
- 1 http://i-know.jp/Joao/
- 1 http://d.hatena.ne.jp/keyword/N-gram
- 1 http://cvs.m17n.org/~akr/diary/2006-03.html
- 1 http://b.hatena.ne.jp/t?tag=Statistics&of=300&sort...
- 1 http://b.hatena.ne.jp/otsune/20060821
- 1 http://b.hatena.ne.jp/otsune/
- 1 http://b.hatena.ne.jp/keyword/regexp?sort=eid
- 1 http://b.hatena.ne.jp/keyword/N-gram?of=25&sort=ho...
- 1 http://b.hatena.ne.jp/keyword/ゲド戦記?of=25&sort=...
- 1 http://b.hatena.ne.jp/j0hn/favorite
- 1 http://b.hatena.ne.jp/another/favorite
- 1 http://b.hatena.ne.jp/Schuld/favorite
- 1 はてなアンテナ[whiromatsu]
- 1 はてなアンテナ[snowy]
- 1 はてなアンテナ[sidetail]
- 1 はてなアンテナ[shibudqn]
- 1 はてなアンテナ[rjj]
- 1 はてなアンテナ[ninjin]
- 1 はてなアンテナ[maayamoe]
- 1 はてなアンテナ[le-matin]
- 1 はてなアンテナ[kimpon]
- 1 はてなアンテナ[gau]
- 1 はてなアンテナ[arakik10]
- 1 はてなアンテナ[anisina]
- 1 はてなアンテナ[GridBug]
- 1 はてなアンテナ[Furumizu]
- 1 http://1470.net/mm/recent.html/url